

Small Language Models (1/2) - Bigger isn't always better
Latency, reliability, cost, and privacy might matter more

👋 Welcome to the first edition of the Lay of the Land. Each month, I (why?) pick a technology trend and undertake outside-in-market research for the opportunities they present.
This is article 1/2 of Topic 1: Small Language Models. We’ll discuss the need for SLMs, differentiate them from Large Language Models, and examine how the space has taken shape amidst the great AI race.
Hope you find this useful enough to follow along!
The Swiss Army knife was first produced in 1891. This knife was to be suitable for use by the army in opening canned food and for maintenance of the Swiss service rifle, the Schmidt–Rubin, which required a screwdriver for assembly and disassembly. Karl Esner improved this design with tools attached on both sides of the handle using a special spring mechanism, allowing him to use the same spring to hold them in place. This new knife was patented on 12 June 1897, with a second, smaller cutting blade, a corkscrew, and wood fiber grips, under the name of Schweizer Offiziers- und Sportmesser.

Aside from the 5432 use cases crammed together in one place, the tool’s biggest W has always been its portability. Of course, the GEARWRENCH MEGAMOD can fix more problems. But what’s the point if you can’t carry it in your pocket while trekking in Patagonia during Spring break?
You see where I’m going with this, right? The Swiss Army knife is this month’s protagonist— the reliable, cheaper, and easy-to-carry Small Language Model (SLM). In contrast, the MEGAMOD—its more powerful and widely known cousin—is the Large Language Model (LLM).
I believe there’s room for both.
First up, a quick refresher
Skip to ‘The chinks in the armor’ if you’re up to date with LLMs
Neural Networks (NNs) are a class of machine learning models inspired by the brain's workings. Neurons (interconnected nodes) collect and process inputs and transmit information (forward propagation) across layers to make a prediction. The difference (Loss) between this prediction and the actual value is used to send information back (backward propagation) over the network to further update node weights and minimize Loss. This process is repeated multiple times (epochs) to finally arrive at the optimum weights for the model.
In Language Models we feed Embeddings (words and their semantic relationships represented as vectors (tokens) in a multi-dimensional space), as inputs into NNs, to predict the next token, and attention mechanisms teach the model what’s most important (relative to other tokens in the sequence). A big breakthrough happened when Transformers (an attention mechanism), introduced in 2017, presented an architecture that could calculate attention in parallel, unlocking the ability to efficiently scale Language Models to work with large corpora of data. Magic followed when Transformers met the parallel computing prowess of GPUs (NVDA 📈), and then TPUs, NPUs, and the other PUs that followed.
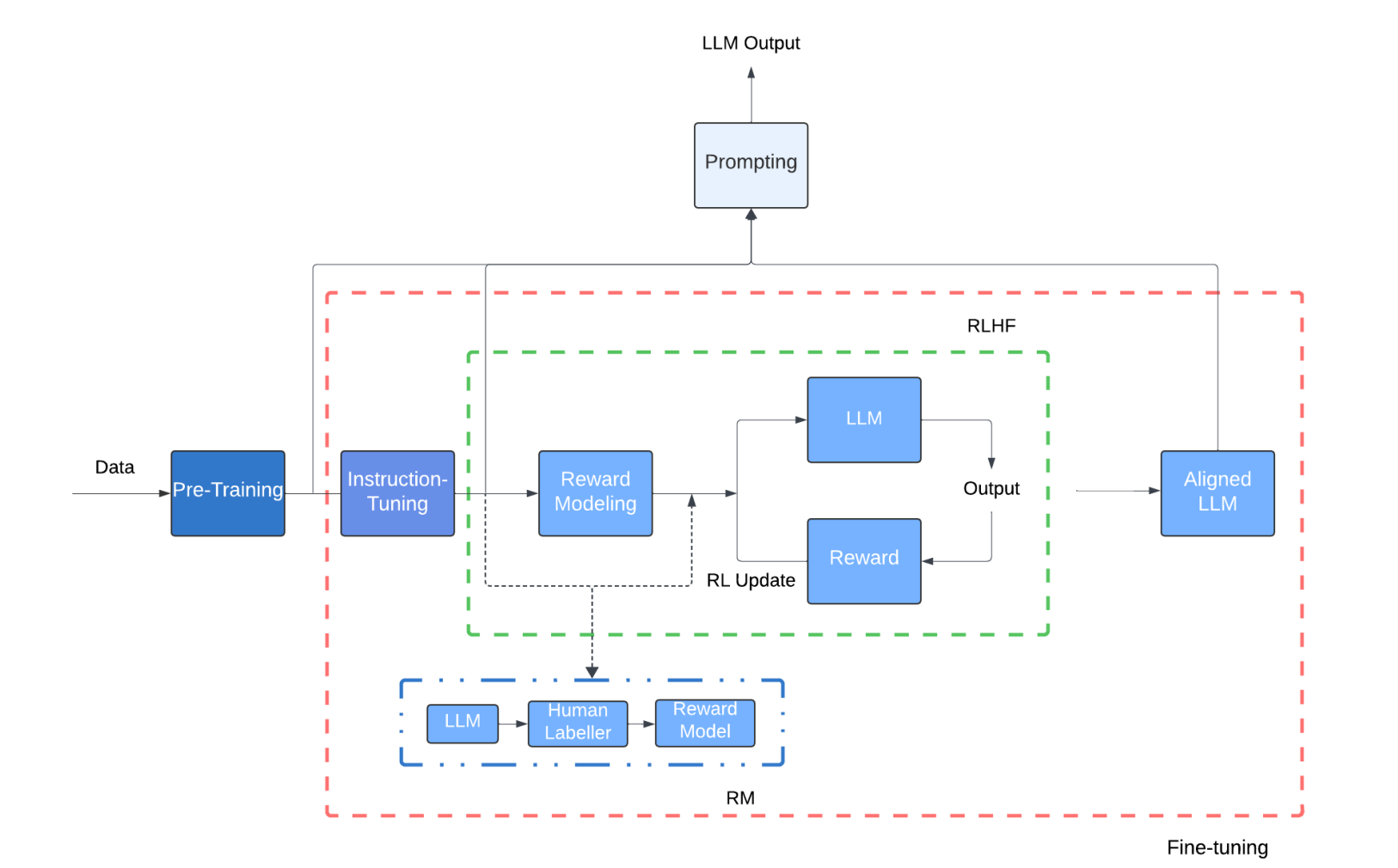
While Google developed BERT to understand their search queries better, OpenAI introduced the pre-train + fine-tune paradigm to develop GPT-1 (117M parameters, parameters ~ weights & biases in a NN) as a text generation model. GPT-1 was fine-tuned to get good at text classification, Q&A, etc by modifying its weights with labeled data (answer keys). The idea that performance could improve with scale was set in motion at this time. GPT-2, trained on 1.5B parameters, was the first signal but the LLM scaling laws were formalized with GPT-3 (140B) - performance followed power-scaling (diminishing) with #parameters, training data, and longer training times. GPT-3 could outperform smaller models without task-specific learning and exhibit in-context learning.
The star was really born when OpenAI took these advancements to the masses with easily consumable distribution channels: ChatGPT and OpenAI APIs. Mega servers balanced billions of queries from across the world and ran Inference (the process of using a trained model to generate responses to new data) on stored models to solve our homework.

Many more models popped up and were made available as :
Proprietary/closed-source models: like the OpenAI GPT series and the Claude series are owned, controlled, and maintained by companies and can be accessed through their own applications (monthly subs) or via APIs / managed services (usage-based on input / out tokens).
Open-source models: are pre-trained and their weights/biases are shared under different OSS licenses. Models like Mistral 7B and Falcon 7B (Apache 2.0), MSFT Phi (MIT), and Llama under the Llama commercial guidelines are very permissive and are open for commercial use. These models can be downloaded, self-hosted, and deployed on your servers or can be accessed via APIs from managed services like MSFT Ai Studio / Amazon Bedrock or via inference engines like Cerebrus / Together Ai / Groq.
The outaccelerate challenge 🤺:

Tech giants (MSFT, Google, Meta, AMZ, et al.) and new specialists (OpenAI, Anthropic, Mistral, et al.) then pressed the pedal on the scaling laws and have beaten evaluation benchmark world records every 2 weeks, teased AGI with emergent abilities (reasoning, etc), and increased parameter counts above the Trillion mark with architecture developments like Mixture-of-Experts (think of having 4-5 specialized LLMs with 200-300B parameters each working side by side).
It would be wrong to think of these mega models as single monolithic LLMs because they can do so much more. Claude introduces its 3.5 sonnet model as an AI system that combines core language modeling with multimodal capabilities (vision, code analysis, document understanding), constitutional AI frameworks (for safety and ethical use), and multiple specialized models working together.
Note: These multimodal capabilities != the architecture behind MidJourney, DALL.E, or even SORA which uses Latent Diffusion Models to put cat DJs on the moon.
Reasoning is the hottest frontier in Language Modeling today. Unlocking reasoning would make these systems more autonomous in making decisions and, hence, more intelligent. The latest paradigm shifts computation from pre-training and post-training to inference to get the model to think more, consider multiple possibilities (with reinforcement learning) and converge upon the best course of action. OpenAI’s O1 series faces tough competition from the open-source DeepSeek R1, and the results are beyond promising.

Agents: are autonomous LM-powered systems that can take real actions on your behalf. Cracking reasoning could be a big step toward extending the power of agents beyond automation and low-risk tasks. We would also need to mitigate risks that could derail task executions.
Summing the last 4 minutes up, it kinda seems that the winner is going to be the biggest model running on the most powerful hardware being used to build the most intelligent and autonomous system right? Nope.
The chink(s) in the armor
LLMs are great but they fall short when it comes to the following -
Running them on your phone (personal devices):
Hardware limitations: GPT 4 requires 500GB+ to deploy and 4o requires 200GB. You can’t fit this in your mobile phone. Also, there’s no way your battery-powered phone can bring the 300-500 A100 GPU core seconds to run a single inference on the 4o.
Why do you need it to run on your device? Ever heard of the cloud? 🙄
Latency: GPT 4o would require 350-400ms to deliver a translation task over the cloud. The same model if hosted on-device would still need 100-150 ms while avoiding network latency. Real-time translation would require a latency of 40-60ms. Autocorrect on your iPhone runs at 35ms latency.
Reliability: DNS resolution errors (503 Service Unavailable), Connection timeout (HTTP 408), 429 Too Many Requests, Latency spikes.
Privacy: Sending all your email data to an LM hosted for summarization and prioritization sounds kinda scary, doesn't it? Sending it to a private cloud is reassuring but then again - latency and reliability.
Hmmm, so LLMs on-device is a challenge.
Specialization/domain adaptation:
Remember pre-train - fine-tune? The paradigm is being used by domain leaders (law, healthcare, finance, etc) to create vertical language models to advance their field. The bigger the LLM, the more costly/inefficient it is to fine-tune. Verticalized solutions often don’t need the expansive knowledge pre-trained into an LLM - making the cost completely unjustified.

Operational inference costs:
The application layer building solutions with LMs have to bear the managed service API costs or need to bear server costs to host OS models. The bigger the model, the costlier the compute. Similar to specialization, many of these applications don’t need the SoTA (state-of-the-art) to provide value.
The solution?
Schweizer Offiziers-und Sportmesser
A small language model is a neural network with relatively few parameters (typically millions to a few billion - I will use an 8B cut) compared to large language models. These models trade off capabilities and knowledge breadth for faster performance, lower computing requirements, and easier deployment on consumer devices.
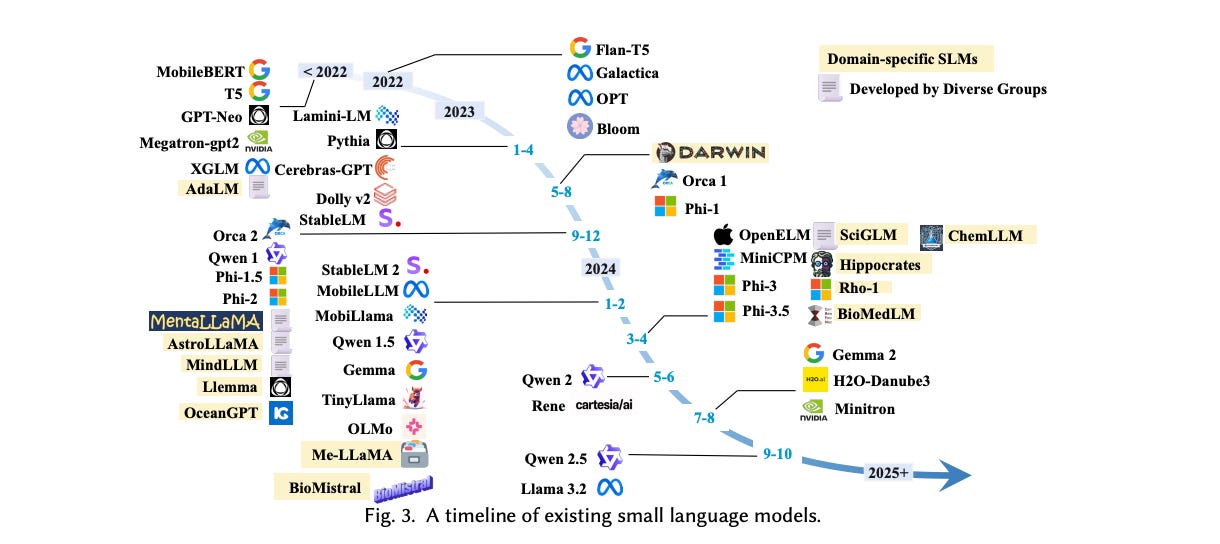
Technically speaking BERT is the first small language model but hey that was not intentionally small. The science of intentionally keeping models small for trade-off benefits began in the -
Compression Era (2019-2021): This period marked the first deliberate attempts to create smaller, efficient models. The breakthrough came with DistilBERT (Huggingface), which pioneered knowledge distillation - imagine a teacher-student relationship where a large model (BERT) teaches a smaller one - cutting model size by 40% while keeping 97% of its capabilities. Other compression methods include - Pruning (removing redundant layers/ parameters) and Quantization (reducing precision). MSFT Fastformers combined all three to make Transformers ‘faster’.
Small from Scratch Era (2021-2023): the focus shifted from compressing large models to building small models from scratch. New architectures were specifically designed for efficiency - training infrastructure with built-in optimizers, efficient attention mechanisms, parameter-sharing, and better tokenization created Small Models that performed pretty well - GPT-NEO, and OPT-175 are all graduates of this era!
Specialized Optimization Era (2023+): Microsoft's Phi series marked the beginning of specialized small models. Models were better adapted to solve specific problems using better task-specific fine-tuning (and/or Reinforcement Learning) and high-quality synthetic data. Synthetic data (generated using LLMs) can fill scarcity by generating realistic but artificial data that mimics the characteristics of real data. It can also add additional context (think code comments) and multiple iterations that would have been very cumbersome for humans to generate. Another big priority for this era is to create hardware-optimized models.
Chinks = fixed
Remember the LLM armor chinks. Here’s how SLMs are the fix -
Gemini Nano 2 is used by Google in their Pixel 8 smartphone to enable offline and on-device voice recording summarization and smart replies.
Whisper JAX (a small, efficient version of OpenAI's Whisper speech recognition model, optimized for JAX) is used in a live streaming application to provide real-time transcription reliably to viewers.
Mistral 7B fine-tuned (cost-effective domain adaptation) on the Bitext Retail Banking Customer Service dataset is used by a retail bank to power a customer service chatbot, providing fast and accurate responses to common banking inquiries.
DistilBERT is used by a leading electronic health record (EHR) software provider to handle patient inquiries while preserving data privacy within their systems.
Cleanlab Studio uses SLMs (optimizing inference costs) to analyze customer service requests and identify potential issues in datasets, helping businesses improve the quality of their data and the performance of their language models.
Convinced that SLMs are here to stay? I am.
Next up - Market landscape, risks, and more
That’s all for today’s article folks! I hope it was a useful refresher on language models and also made a case for Small Language Models. In the upcoming weeks, we will evaluate the Market Demand for SLMs, chart out the competitive landscape for supply, explore some extrinsic risks, and finally make some predictions for the space.
Thanks so much for reading! See you soon with a new post!
If you liked the content and would like to support my efforts, here are some ways to help:
Subscribe! It’ll help me get new updates to you easily
Please spread the word - it’s always super encouraging when more folks engage with your project. Any kind of S/O would be much appreciated.
Drop your constructive thoughts in the comments below - point out mistakes, suggest alternate angles, requests for future topics, or post other helpful resources