

Small language models (2/2) - The Lay of the Land
What's cooking and who's cooking - applications of SLMs and their providers

👋 Welcome to another edition of the Lay of the Land. Each month, I (why?) pick a technology trend and undertake outside-in-market research for the opportunities they present.
This is article 2/2 of Topic 1: Small Language Models. Today, we will evaluate the market for SLMs, chart out the supply landscape, explore some extrinsic risks, and finally make some predictions.
I hope you find this useful enough to follow along!
Btw, If you missed Article 1, I recommend checking it out first. We covered what SLMs are, their defining characteristics, and why they matter

Quick recap: There is a clear niche for SLMs! Particularly -
in offline or resource-constrained scenarios (when the device can’t always rely on stable or fast connectivity).
when low latency and reliability are important
for high volume, low complexity use cases (enabling inference at lower cost).
in privacy-sensitive contexts (where users prefer devices over the cloud).
Today’s piece builds on these insights by looking at how these capabilities translate into real-world use cases and what kind of market demand they might drive. For starters, I picked/categorized the most talked about use cases where SLMs are expected to have advantages. Time to critique 🧐

On-device: focus on size, battery consumption, and compute efficiency.
AI-Enabled Smartphones & Laptops:
Efficient language models amongst other traditional ML models can run on your laptop GPUs with the right middleware. However, using GPUs for inference could zap out your battery life and hence there has been a significant push for AI-first co-processors like the Apple Neural Engine, Qualcomm Snapdragon, MSFT NPUs - hardware from Intel, Xilinx, ARM, etc, which are a lot more power efficient. These co-processors are particularly important for mobile devices, which are only slightly bigger than your laptop GPU cooling fans.
Small language models with low inference compute requirements and size, can use these capabilities to undertake NLP tasks like machine translation, text autocorrect, and personal assistant queries—especially when users need offline capability or want to reduce data sent to cloud servers. These devices can also support other traditional ML models for vision and image manipulation, giving magical (photo bomber elimination) abilities to your phone cameras.
The Chinese smartphone market has been quick to respond to these capabilities and phones with AI capabilities are expected to hit 23% penetration amongst new shipments. That’s a market size of $150B when extrapolated globally.
A winning proprietary SLM could be the new Operating System (OS) - a standardized best performer used in the winner’s products or licensed to OEMs, and used by the developer world while building applications (high). We could also imagine a world where SLMs become a part of the application package (medium) or even a marketplace item, ready to be downloaded and used (low).

IoT Sensors & Wearables:
Small Language Models (SLMs) are considered to be promising integrations into IoT sensors and wearables, enabling on-device processing of text-based feedback such as alerts, logs, and user instructions. This integration would enhance real-time responsiveness and reduce reliance on cloud-based processing. I am personally not a big believer in this application and I feel that traditional ML methods (CNNs, image classifiers, basic Speech to Text commands, etc) can do more with less. However, I feel that a big breakthrough could come with large reasoning models deployed over edge networks, making IoT devices autonomous-ish. However, at the end of the day, it’s a massive market at $1T+ with a fun subcategory called AI-for-IoT pegged at $100B by 2032 - so would recommend revisiting this category in the future.
Cloud: focused on low latency, cheap inference, and ease of adaptation.
Knowledge-Work Copilots:
Think code-completion tools or writing assistants that are integrated into development environments and word processors. While these use cases are better served by LLMs with larger context windows, reading multiple files across your codebase / shared drives, there is an opportunity to hand off smaller / repetitive / and structured tasks to SLMs by adopting a hybrid approach. “Share the Excel formula for calculating NPV from this cashflow table” => SLM, while “Craft a financial evaluation process for a SaaS business” => LLM.
A hybrid approach would reduce costs for Microsoft Excel while also increasing speed to an autocomplete-ish way of working. Similarly, the GitHub copilot of the future could bring the best of Codex and Phi 3.5 mini to 30M developers.
The knowledge-work copilot market is massive. GitHub Copilot already has 1.5 million paid users, and the number of paid seats across MSFT’s office is north of 400 million! Any efficiency/productivity lever for this market would be a big boost and the IDE / Word processor that extends these capabilities would be the platform of choice for knowledge workers and their employers.
Enterprise conversational AI:
Large enterprises with heavy customer interactions (e.g., e-commerce, telecom, SaaS) are favoring smaller, efficient models for their customer-facing chatbots, to reduce cloud computing costs and enable real-time responses without high latency. This becomes even more pronounced when the enterprise needs heavy control w.r.t data privacy.
A powerful small language model like the Phi 3.5/4 with good enough reasoning capabilities coupled with a RAG system (that takes all your company data, converts it into vector embeddings, and feeds the easy-for-the-slm-to-understand data as extra context), could be a cost-effective way to set up a customer support chatbot on your website. Conversational AI is a 10B+ market and is in the middle of a major disruption with language models destroying rule-based systems (80% + customers leaving the chat). These models can also double down as agents when equipped with ways to undertake simple tasks like booking demo calls or retrieving documentation. They could also decide for themselves when the now down-sized customer support team should engage.
Verdict: SLMs are a solid choice for this use case!
Side note: The RAG motion is getting some slack for accuracy issues. An alternative in the future could be models with large enough context windows.
High volume + real-time translation, captioning, and content moderation:
a) SLMs are pretty good (SoTA even) at Natural Language Processing
b) LLMs are terrible with latency
c) LLMs for high-volume use cases would be expensive
a + b + c = This is a pretty solid use case!
These applications could be extremely beneficial for accurate and accessible delivery of content and would be used in both personal and professional capacities by a large audience.
However, two big challenges that I can foresee for this use case are: 1) RoI for these use cases is difficult to assess 2) accuracy. However, with improving technology, efficient transformer-based language models and the services that use them could be the default here.
Fine-Tuned Narrow-Domain Experts:
Industries like law, medicine, finance, or academia often need domain-specific models. SLMs allow these verticals to spin up efficient, specialized solutions that remain cost-effective and can be retrained or updated quickly. These models are built with continuous pre-training (train the model with more data) of small languages with high-quality content, followed by specialized fine-tuning or instruction-tuning to perform tasks like Q&A and legal document verification. In domains with abundant corpora, you could also train a general model from scratch, and fine-tune it using SFT. Distilling general capabilities from LLMs while integrating domain-specific knowledge from corpora is another method for developing domain-specific SLMs

By virtue of re-calibrating what’s important and by adding high-quality data, these domain-adapted specialist SLMs sometimes perform better than powerful LLMs in vertical-specific evaluations.

This is a very powerful use case and can be used to create copilots for researchers/scientists or automate redundant tasks for white-collar specialists unlocking niche but high-value returns. Harvey (legal, $3B), Inceptive (bio, $300M), and Hippocratic (Healthcare, $1.65B) are proof that there is a lot of value held in AI-domain experts and the SLMs powering them.
My only concern for the category is the role of reasoning in the future of these categories. If LLMs with reasoning abilities become table stakes, the larger cost of training becomes one worth pursuing.
SLMs for LLMs:
SLMs could be the Robin to LLM’s Batman. They could filter, evaluate, and refine LLM outputs, acting as a lightweight quality control layer before the final response hits the user. They could also be handy for pre-processing and post-processing—extracting key details from prompts before feeding them to an LLM or compressing outputs to reduce verbosity. This could be a very strong use case that can bring in high ROI in the context of building the best LLM. Here’s my wifey talking about how SLM-powered AI judges could be the key to unlocking AI Agents.
LOTL Use-case Score™
I love a quick scoring system, so here’s a 1–5 rating on four dimensions: Reach (market size), Impact (ROI potential), Confidence (will it succeed? If yes, is this the best solution?), and Effort (how difficult is to implement). Then we add them (subtract effort). Unscientific, but helpful for a back-of-the-napkin check.

This table kinda represents my mental model for what’s important and why.
TLDR - there is a sizable market for these little guys but some use cases are more promising than others. Now, let’s find out how the tech world is tapping into it.
It takes a village to raise an SLM
While model building gets all the glitz and glamour, there are so many shovels to this language model gold rush (we all know an NVIDIA millionaire). Here’s my Canva project describing the value chain behind building and using Small Language Models:

and here’s a one-line description of each category in the image:
Data Collection / Gen – generate, synthesize, and collect datasets
Data Labeling – Tools and services that annotate and label data for training
Data Governance – manage, secure, and ensure compliance of data usage.
Compute for Training – Hardware and cloud access to computational power
Training Frameworks / Middleware – Libraries and tools
Model Builders – create, train, deploy, and improve AI models
Model Monitoring and Eval – track, and evaluate model performance
Cloud Deployment / Inference – AI model deployment and inference via cloud
On-Device Deployment / Inference – Hardware and software solutions enabling AI model execution directly on edge devices.
As you can see from the crowded image, there is a lot of exciting work happening across this value chain and I hope to dig deeper in future articles. But for now, let’s focus on the central pillar of this system:
Model builders balance tradeoffs and pull on these levers - 1) Model architecture - transformer variant, attention mechanisms, tokenization strategies, etc. 2) Data selection and pre-processing - online deduplication, curriculum learning (feeding simpler examples first), and active dataset pruning. 3) Optimization & compression, to develop the right model. With SLMs, they also focus on 4) Inference optimization - hardware optimizations, speculative decoding (predicting multiple tokens together), etc to make the models more useable. The notable players here are research labs at Big Tech organizations (MSFT, META, GOOGL, Alibaba, APPL) as well as AI-first labs at Cerebras, Eleuther, Hugging Face, etc.
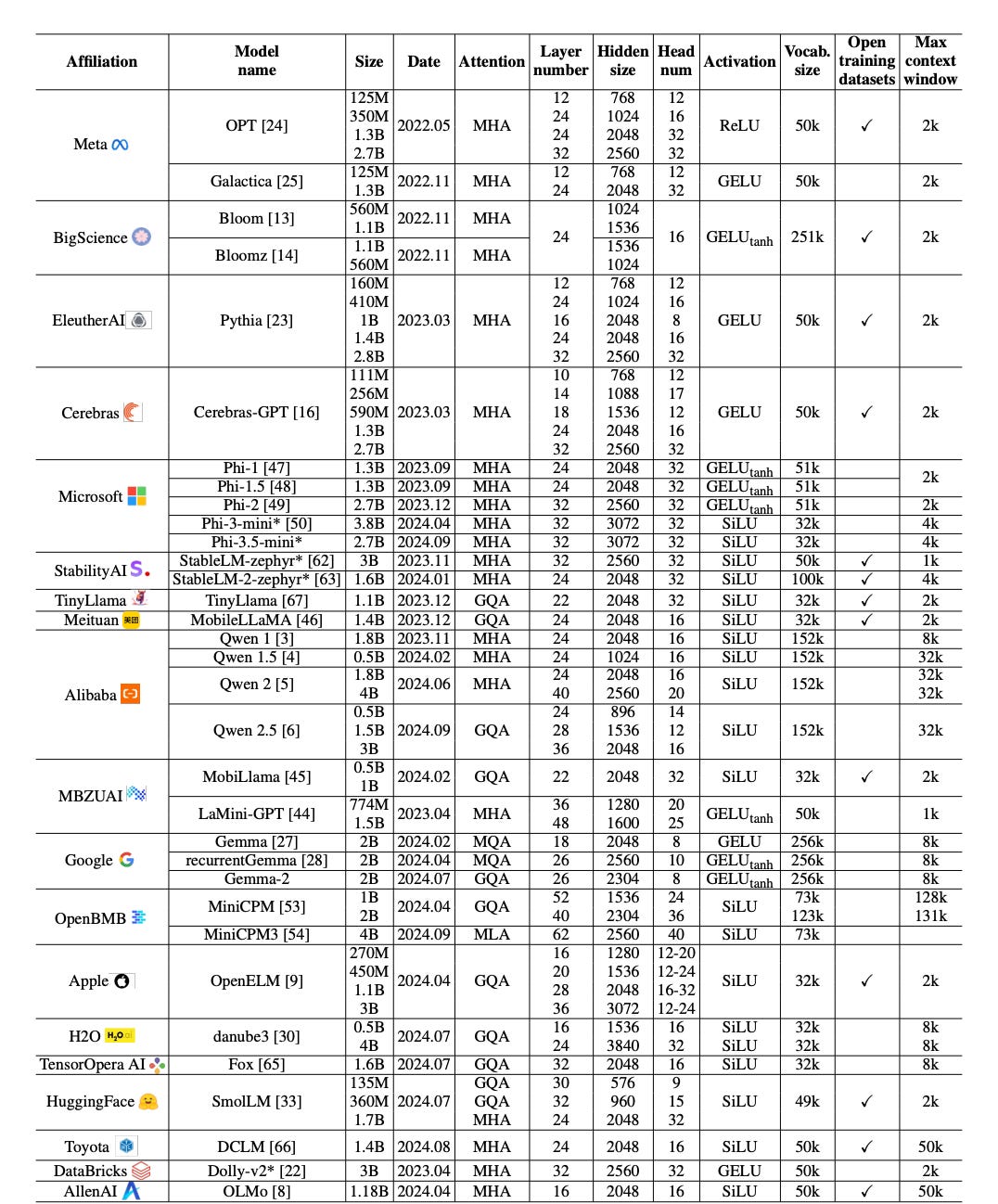
These models have varied levels of performance across different tasks…

and they have varied levels of performance when deployed on different platforms - mostly as a function of their size and due to smart hardware optimization.

There is no single one-size-fits-all SLM out there. Picking the right model is a tradeoff between size, speed, and quality. Also, this is still a very volatile (in a good way) supply market with breakthroughs dropping every two days.
Editor’s pick: noteworthy SLMs
SLMs for on-device use: Compact + low power consumption + efficient inference.
MobiLlama is designed explicitly for on-device AI, with parameter-sharing optimizations for better power efficiency.
SLMs for Fine-Tuning: best for rapid adaptation and instruction tuning.
Phi-3.5-mini-instrust (3.8B) is optimized for fine-tuning on high-quality reasoning-intensive tasks.
SLMs for High Volume, Low Latency NLP: Models that handle bulk natural language understanding with low latency.
Qwen 2.5 (3B) performs the best across relevant evals - IFEval, MATH, GPQA and is very fast and efficient.
Time to consider some of the risks
Like all good things in life, SLMs also come with caveats
Technology risks
Accuracy vs. LLMs: There’s a reason LLMs are big. They know more stuff. SLMs might miss edge cases or handle fewer languages.
Maintenance Overhead: If you have 10 specialized SLMs in production, that’s 10 pipelines.
Security & Privacy: On-device is “private,” but if that device is hacked, the model or data might be compromised.
Bias & Fairness: Smaller training sets can sometimes bake in bigger biases. Tread carefully.
Market risks - Porter’s Five Forces (Because MBA 😌 )
Threat of New Entrants: High. Open source is leveling the playing field.
Bargaining Power of Suppliers: Chip vendors (NVIDIA, etc.) still have muscle.
Bargaining Power of Buyers: Enterprises can switch to open-source if they hate your pricing.
Threat of Substitutes: Giant LLMs get cheaper and smaller (quantization) every day. If they can optimize inference enough, SLM might lose some luster.
Competitive Rivalry: Exploding. Every cloud or AI vendor is rolling out “lightweight” solutions.
Some predictions
There will be breakthroughs in hardware acceleration: Apple, MSFT, Google, NVIDIA—everyone invests in specialized chips for SLM inference. Pruning, quantization, and all that good stuff become standard.
SLMs will increasingly power on-device applications
Enterprises will continue optimizing for cost and latency and hence will prioritize SLMs
Hybrid Setups: A small model for 80% of queries, then hand off the rest to a big LLM or a human - hitting the cost/latency sweet spot.
Specialized Startups: Expect a parade of new entrants shipping domain-specific SLMs (like “legal SLM” or “radiology SLM”).
But also,
SLMs may be outpaced by optimized LLM inference and LLM quantization
And with that…

Thanks so much for reading! See you soon with a new topic - I am thinking, Model Eval or Spatial Computing, or even Private Space. LYAK soon!
If you liked the content and would like to support my efforts, here are some ways:
Subscribe! It’ll help me get new updates to you easily
Please spread the word - it’s always super encouraging when more folks engage with your project. Any S/O would be much appreciated.
Drop your constructive thoughts in the comments below - point out mistakes, suggest alternate angles, requests for future topics, or post other helpful resources