

AI Inference (3/3) - As a service
Meet the gatekeepers of AI inference
👋 Welcome to another edition of the Lay of the Land. Each month, I (why?) pick a technology trend and undertake outside-in-market research for the opportunities they present.
This is article 3/3 of Topic 2: AI inference. You can buy hardware for inference, lease and install, or tap into it, on demand, with APIs. Today, we’ll map the supplier landscape for the latter two. Disclaimer: This one is long.
I hope you find this useful enough to follow along!
This is part 3 of a 3-part series about AI inference. I strongly recommend that you check out the first two posts if you’re new to the topic.



If you’re Meta, Tesla, Tencent, or a supercomputer center in Switzerland, it would make sense for you to meet your LLM inference needs by making your already powerful server farms AI-ready, buying and installing GPU servers (trivialized, obviously). You’ve already invested in data center infrastructure, so adding specialized hardware is most likely in your wheelhouse. But for most consumers of AI inference, the hassle of financing, constructing, and managing AI compute is not worth it.

The solution? Simple and tested. Familiarized by the SaaS<>High-Performance Computing way of life from the past two decades, AI servers, like other computing servers, could be built and managed by a few and accessed by many, for a fee.
You can rent / lease raw GPU capacity, host models, and run inference
You can run on-demand inference on models hosted on someone else’s GPUs
Two different approaches, varied by costs, ease of setup, and bundled services (easy fine-tuning, vector storage, etc).
Part 1: AI infrastructure as a service
Suppliers in this category,
Lease, buy, or build data centres - from scratch or co-locate.
Ensure reliable power, cooling, security, and high-speed networking.
Acquire and install GPU servers
Build and extend software for GPU provisioning (SLURM / Kubernetes)
Lease GPU capacity to customers over the internet
Monitor usage, bill the customer, and maintain shop
A GPU cloud provider makes most of their money from multi-year contracts that reserve GPU capacity with upfront advance payments (typically 15-20%). The bill would include GPU cloud compute, accompanied by storage (object + file) server bills (billed per GB/mo) and managed software costs.
Since there is little differentiation in the hardware (GPUs) hosted (unless there is a different mix of accelerators), this segment relies on the following for competitive differentiation:
Datacenter design: Accelerator selection, decisions on power and cooling systems, rack placements design, networking and storage systems, and facility layout & rack design. For example, many data centers will need to upgrade to liquid cooling in order to support the rack density necessary for the NVIDIA Blackwell series.
Hardware utilization: MFUs or Model Flop Utilization measures whether GPUs are utilized well with better allocation, batching, and other middleware-led efficiency hunts.
Operational efficiency: PUE / WUE (power/water usage effectiveness) is the additional energy and water requirements that enable a datacenter and is a function of design and operating discipline. PUE - Industry average 1.6. Hyperscalers 1.1. MSFT even tested an underwater datacenter, which required less cooling energy.
Reliability: Outages are a no-go. Cooling failures can affect equipment life.
Capital budgeting: A large part (80 %+) of the monthly OpEx for a datacenter is capital costs for the upfront investment. Your cost of capital becomes king.
Utility costs: Access to cheap energy and water. Colder climates can reduce cooling requirements.
Size: The bigger, the better - economies-of-scale.
Security - physical and digital
Other services: middleware know-how, access management, data governance
Direct costs of datacenters include rent, utilities including power, labor, depreciation, and amortization for semiconductor systems, as well as those for power installation, distribution systems, and cloud delivery software. Another major cost line is colocation service costs for data center vendors (if applicable), usually paid as monthly fees, which can go up with bandwidth used. S&M is likely high in established hyperscalers but gets diluted as a percentage of revenue for the upstarts because of heavy revenue concentration in a few customers.
Hyperscalers
The first big AI datacenter was introduced to the world when MSFT built a 10k NVIDIA V100 AI supercomputer (5th largest at the time) for OpenAI. Today, AI computing is THE profit engine for these tech giants. They enjoy unique competitive advantages in the form of technical know-how, economies of scale w.r.t IT equipment as well as energy and cooling equipment, better PUE/WUE, and a low cost of capital because of their sheer size and diversified interests.

Azure
cannonballed into AI with OpenAI and is arguably in the lead as the #1 AI compute provider. In fiscal Q2 FY25, Azure revenue surged 31 % YoY and pushed Microsoft’s AI services to a $13 billion run-rate, more than doubling in twelve months. That momentum now rides on an estate of 300-plus datacenters across 60 regions, and a cap-ex line that jumped to $22.6 billion last quarter - up ~30 % YoY - with “almost all” of it pointed at cloud-and-AI build-outs.
MSFT stitched itself to OpenAI early (infusing $14B+) as the sole compute provider, and built out GPU capacity to bake AI into its enterprise software empire (Office, Teams, GitHub). OpenAI pays rent for compute and a share of its profits, Microsoft gets compute rent and IP rights to use OpenAI models in their products. Extra capacity was to be shared with the world through a comprehensive software platform - Azure ML, Azure Virtual Machines, Azure Kubernetes, et al, and a services army that’s best friends with almost all of the Fortune 500.

On the GPU side, Microsoft remains NVIDIA’s favorite hyperscaler but is hedging with home-grown silicon: Maia accelerators for inference, Cobalt CPUs for general compute, and Azure Boost DPUs that offload storage/networking so H-class GPUs stay busy. MSFT is also investing in edge computing and on-device inference with NPUs and Azure Stack Edge/MEC.
Power and capacity are the next choke-point, so Microsoft is betting wide and early: a 50 MW fusion PPA with Helion (delivery 2028), a 48-hour hydrogen-fuel-cell datacenter demo in Wyoming, and liquid-cooling retrofits for next-gen GPU racks. New regions keep popping—Thailand, Italy, Mexico, Saudi Arabia, Spain—but guidance now emphasizes “utilization discipline” over raw land-grab as the company pivots from expansion to sweat-the-asset.
AWS
is Amazon’s key profit engine, accounting for 17% of total revenue and 50.1% of Amazon’s operating income. That’s $39.8 billion in segment-level profit, up 62% from $24.6 billion a year ago, driven by a resurgence in cloud demand and aggressive AI infrastructure bets.
Late to the AI datacenter arms race, AWS is making up for lost time. Anthropic is to AWS what OpenAI is to Azure, and selling AI Compute is a major priority within AWS. In order to meet their demand, AWS is deploying billions into new regional builds - Sweden, Thailand, the Middle East, and making strategic moves like acquiring a nuclear-powered datacenter campus in Pennsylvania. Similar to Azure, AWS has built a comprehensive software stack comprising Sagemaker, AWS EKS, Data lakes, to work alongside the goated AWS compute/storage servers.
Differentiation? Custom silicon (via Annapurna Labs acquisition). AWS is pushing hard to save on margins with Inferentia for inference, and Trainium2 that powers Anthropic’s (a major Amazon AI lab investment) Project Rainier — a massive supercomputing cluster purpose-built for next-gen LLM training. Trainium3 is already in the oven, with a sneak peek promised for later this year.
“Building outstanding performant chips that deliver leading price performance has become a core strength of AWS” - Andy Jassy
GCP, Oracle, Alibaba
While AWS and Azure dominate, a second tier of players - Google Cloud (GCP), Oracle Cloud Infrastructure (OCI), and Alibaba Cloud - is carving out a meaningful share with differentiated strategies.
GCP is a strong contender with technical depth. As the birthplace of the Transformer and home to the TPU (now in its v5e version), Google offers a vertically integrated stack optimized for large-scale inference, TPUs boasting a considerable lead in the ASICs race over Inferentia and Maia. Along with OCI, GCP is the fastest-growing hyperscaler, posting $42B in 2024 cloud revenue and recently turning profitable, though it still trails AWS and Azure with ~11% market share, setup difficulties, and networking gaps affecting adoption.
Oracle Cloud (OCI), in contrast, has positioned itself as the value player for inference, offering competitive pricing on A100/H100 bare-metal clusters and generous bandwidth terms. While Oracle holds just ~2–3% of global market share, its infrastructure is increasingly favored by the cost-sensitive. This also includes a large contract from OpenAI, which they service themselves as well as through partnerships (Crusoe).
Meanwhile, Alibaba Cloud remains the inference leader in China (although ByteDance’s own inference scale is huge), offering localized access to NVIDIA GPUs and proprietary silicon like the Hanguang 800. With an ecosystem spanning e-commerce, payments, and logistics, it benefits from deep vertical integration and regulatory alignment. Though geopolitical factors have limited its global expansion, Alibaba still commands ~39% market share in China and ~4% globally, generating $15B in FY2024 cloud revenue, much of it increasingly tied to AI compute and model APIs.

While hyperscalers are growing and scaling capacity, there are new entrants out to grab a valuable piece of the pie:
Third-party pureplay GPU clouds with their homogenous workloads do not need to worry about advanced database services, block storage, security guarantees for multi-tenancy, APIs for various 3rd party service providers, or, in many cases, even virtualization.
Better MFUs
Supplier relationships - NVIDIA Cloud Partner program (re: NVIDIA equipping their friends as a hedge against hyperscalers)
Faster datacenter turnarounds and strategic financing
Undercutting hyperscaler™ price premiums
AI-only hyperscalers
“The generalized cloud infrastructure that drove the cloud revolution beginning in the 2000s was built to host websites, databases, and SaaS apps that have fundamentally different needs than the high performance requirements of AI. As workloads and technologies evolve, so too must the infrastructure and cloud software and services that power them. We believe we are at the start of a new cloud era that will drive the AI revolution.” - Coreweave, S-1
Coreweave
IPO’d in March 2025, pitching investors on a pure-play “AI Hyperscaler™” model purpose-built for the LLM and generative AI boom. The S-1 filing showed FY2024 revenue of $1.9B (+737% YoY), a $15B backlog of take-or-pay GPU contracts, and heavy reliance on asset-backed debt (over $14.5B GPU-backed ABS raised) to fund aggressive growth.
Their fleet consists of 32 liquid-cooled data centers housing over 250,000 GPUs, with 360 MW active and another 1.3 GW contracted. CoreWeave differentiates itself by stripping traditional cloud complexity—no virtualization layers, bare-metal GPU clusters with dedicated DPUs for network/storage offloading, and its proprietary “Mission Control” telemetry software. The payoff, they claim, is a 20% higher GPU utilization (MFU), significantly lower latency (shaving critical microseconds for inference-heavy workloads), and a pricing advantage at roughly $4.25/hr per H100 GPU (cheaper than hyperscalers’ comparable instances, while maintaining >50% gross margins).
They have customers in Microsoft, Meta, Cohere, Mistral, Jane Street, and recently signed a substantial five-year, $11.9B OpenAI deal. However, concentration risk is real, as just two customers made up 77% of 2024 sales, a vulnerability flagged by analysts. Strategically, CoreWeave is best friends with NVIDIA and enjoys first-call access to cutting-edge silicon, consistently being first-to-market with GPUs like H100, H200, GH200, and GB200 NVL72—often deploying these weeks ahead of AWS or Azure.
I wouldn’t bet on Coreweave to come out above the hyperscalers, because of a technological edge, but I believe there is space for a stakeholder management smart, finance-type founder, capital budgeting expert company to find a niche for itself while the giants battle it out. A niche that the following players would also hope to capture.
Lambda and Crusoe
Lambda Labs and Crusoe Energy take two different approaches but share the common goal of lowering costs. Lambda Labs caters to developers and smaller enterprises by offering competitively priced GPU instances, such as NVIDIA H100 PCIe GPUs at approximately $2.49 per hour.
Conversely, Crusoe Energy leverages stranded natural gas to power its data centers, converting otherwise wasted energy into electricity. This approach enables Crusoe to achieve significantly lower operational costs, exemplified by its $3.5 billion investment in a data center campus in Abilene, Texas. The project, potentially qualifying for substantial tax abatements, underscores Crusoe's commitment to sustainable and cost-effective large-scale compute solutions.
Some other notable GPU cloud players include:
Nebius 🇪🇺 (as big as Crusoe/Lambda), ~cheapest GPU clouds ($1.5/GPU hr)
Together AI (more about them soon)
Regional/sovereign clouds - Jio / Yotto 🇮🇳, G42 🇦🇪, GDS/NTT 🇨🇳, STT 🇸🇬
Aggregators, brokers, and traders (small deployments for inference)
VCs offering an extra perk - Oxygen from a16z
Now, let’s move on to approach 2 for running inference.
Part 2: AI platform as a service
Instead of managing raw GPU infrastructure, many users opt for a higher-level abstraction - a platform for building with 3rd party inference. These platforms handle the complexity of model hosting, deployment, and scaling so developers can simply plug into an API and run inference. This means no setup hassle and, more importantly, no payments for idle GPU time. This also means that you could switch between models based on use cases and inference reliability. Such platforms,
Rent/lease/own GPU compute
Host models in two broad ways
Option 1: for serverless serving:
Develop/ acquire/ license models and load them up on GPUs to be used by multiple end-customers (resell access to models)
Option 2: for managed deployment:
Let a customer load model weights on a dedicated, well-configured GPU instance
Provide easy-to-use SDKs or REST/gRPC endpoints so customers can integrate inference into their applications.
Meter usage (token count, machine hours) and generate invoices.
Monitor, update, and maintain.
Build a platform around the inference endpoints with AI developer tooling - telemetry, eval, fine-tuning, search, RAG, data processing, workflow orchestration, and more.
The serverless API model was arguably first introduced when OpenAI extended developer APIs to run inference on GPT-3. It became a category when companies realized they could make money by extending inference APIs to open-source models and eliminating the setup difficulties that many Applied AI scientists and product engineers weren't fond of. It had become quite trivial for these firms to rent some GPUs and start utilizing libraries such as vLLM, TensorRT-LLM, and PyTorch to serve open-source models on both Nvidia and AMD GPUs. The category further added value by bundling this compute with a comprehensive set of AI development tools.
The different sources for competitive differentiation in this category are:
Underlying infrastructure - accelerator used/datacenter capacity can make a mountain of difference w.r.t latency, costs, and throughput
Deployment modes supported - serverless or managed deployment, or both, give developers flexibility to BYOM (bring your own models), to be used in the place of or alongside curated models.
Model catalog - curated models made available out of the box. Proprietary access and exclusive partnerships become an edge.
Security, compliance, and reliability - no sloppy data leaks, hacks, great uptimes
Inference engine stack - proprietary middleware to host and access models or accessible open source alternatives like vLLM
Inference optimization capabilities - inference time optimizations, like attention caching, batching queries to improve GPU utilization, quantizing models to lower precisions, and more.
Developer ecosystem and tooling - a system that lets you do inference-time evaluation, set up governance and content safety guardrails, complement your model with a knowledge database and search, and other production readiness flows.
Modular AI - orchestrate flows, agents, and systems that can
Model customization - while this is more of a training task, some of these platforms let you fine-tune models with additional context,
As you’d imagine, vertical integration becomes a big opportunity. Let’s map out some key players -
MSFT (Azure Foundry and OpenAI services)
Foundry does both serverless endpoints and managed deployments. It has everything you need to customize, host, run, and manage AI-driven applications built in GitHub, Visual Studio, and Copilot Studio, with APIs for all your needs, and boasts a catalog of 1900+ models and services. Foundry services 50% of the Fortune 500 and is positioned as the most reliable and secure AI development playground.
Azure also offers a dedicated OpenAI service within Foundry (paying OpenAI a revenue share as license fees). As a risk-averse enterprise, you’d pay a premium over OpenAI’s APIs for the security, data guarantees, and service contract bundling you get with Microsoft.

Amazon (Bedrock) and Google Vertex
Amazon Bedrock and Google Vertex offer a very similar service to Foundry. A key differentiator is the proprietary model catalog, with Amazon offering the Anthropic suite (and AI21’s) while Vertex holds the keys to Gemini’s and Gemma’s. Other differentiators include integration with respective suites and inference advantages (mostly cost) on custom accelerators.
Together AI - Open-source champion
is building a vertically integrated AI infra stack with an emphasis on the open-source world. The company has raised $533.5M in funding (most recently a $305M Series B in Feb 2025 led by General Catalyst and Prosperity7) at a $3.3B valuation. It serves over 450,000 developers and enterprise customers like Zoom and Quora, offering access to 200+ open-source models via its API and training platform.
GPU capacity comes from a mix of CoreWeave, Lambda Labs, and increasingly, Together’s own datacenter buildouts — including new clusters powered by NVIDIA’s GB200s and H200s.
Tri Dao (of FlashAttention fame) leads Together’s R&D efforts, with performance optimizations like the Together Kernel Collection (TKC), memory-efficient attention, and token throughput boosts baked into the infra. Beyond inference, Together also supports fine-tuning, experiment tracking, data versioning, and scalable model training, making it a full-stack playground for anyone betting on open weights.
Fireworks - Betting on Modular AI
Fireworks AI is a $552M startup and has raised a total of $77 million in funding, including a $52 million Series B round led by Sequoia Capital, with participation from NVIDIA, AMD, and MongoDB Ventures. The company offers a catalog of over 100 state-of-the-art models across text, image, audio, and multimodal formats. Most of their GPU infrastructure is sourced from AWS.
Positioning itself as a leader in Modular AI, Fireworks AI provides developers with tools like FireFunction, a function-calling model for orchestrating multiple models and tools to build cost-efficient and smart flows and agents. They are batting for a world where developers would use routers to assign complex queries to large models and simpler ones to cheaper and more efficient small models. While intuitively a solid plan, such routing could be error-prone and frankly, unnecessary with cheaper inference.
They have also built technological edge in 1) FireOptimizer, an inference engine optimizing model serving for performance and cost, 2) FireOptimus, an LLM inference optimizer that adapts to traffic patterns to enhance latency and quality, and 3) FireAttention v2, a technology enabling rapid model refinement and integration with significant latency improvements.
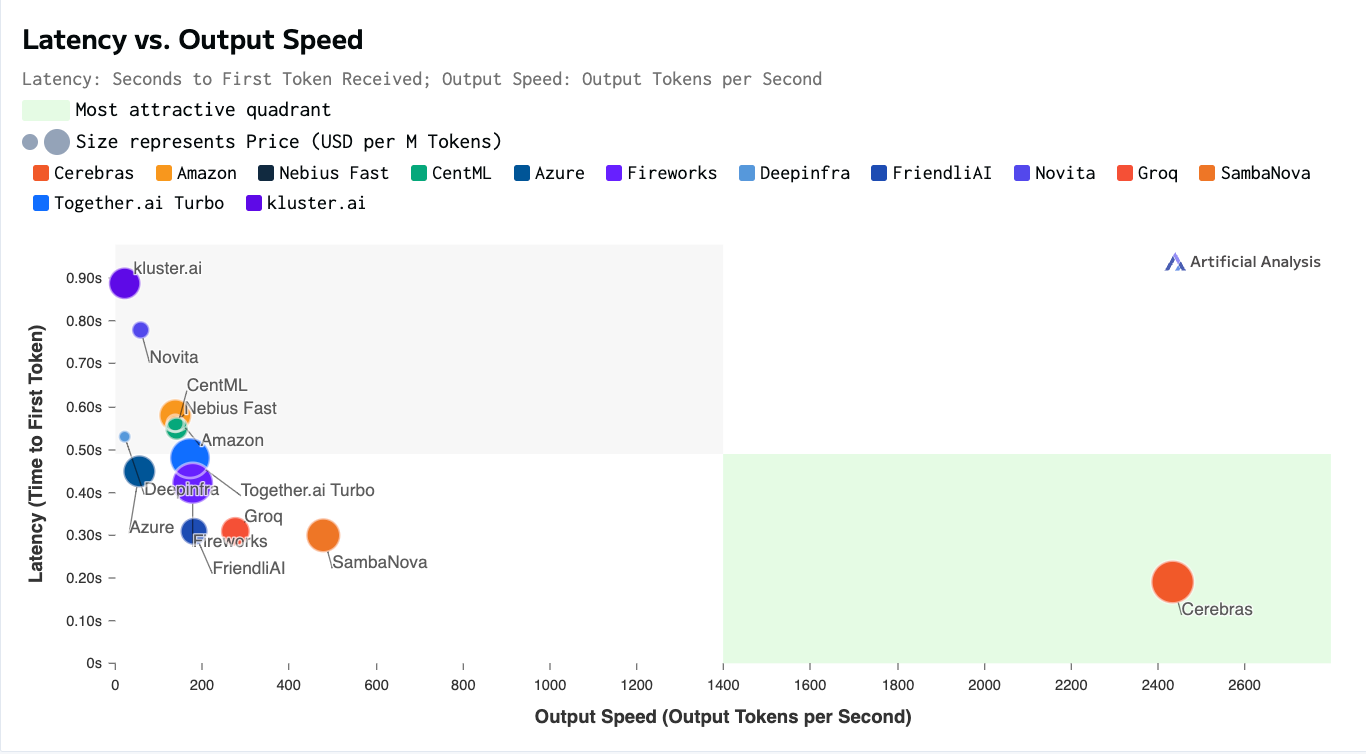
Groq and Cerebras - Need for Speed
Remember the GPU upstarts building a truly differentiated AI accelerator in a bid to take on NVIDIA? We discussed how inherent limitations - Cerebras was too expensive upfront, and Groq needed 100s of LPUs to host a model - made these companies a risky investment for GPU Cloud providers. The solution was for them to vertically integrate and create a GPU cloud and serverless inference solution of their own. And that’s precisely what Groq and Cerebras are up to.
Groq, along with their #1 customer and partner, Aramco Digital in the Middle East, has opened a 19000 LPU inference cluster and offers super-fast inference (for not too large models) for a catalog that includes Llama, DeepSeek, Mixtral, Qwen, and Whisper via their inference console. The product has a free API key and boasts 1M+ developers as users. Their products are clearly positioned for speed and also support ASR and STT models - probably built for real-time voice inference. They also have a GPU cloud and GPU rack/cluster offerings for more enterprise customers.
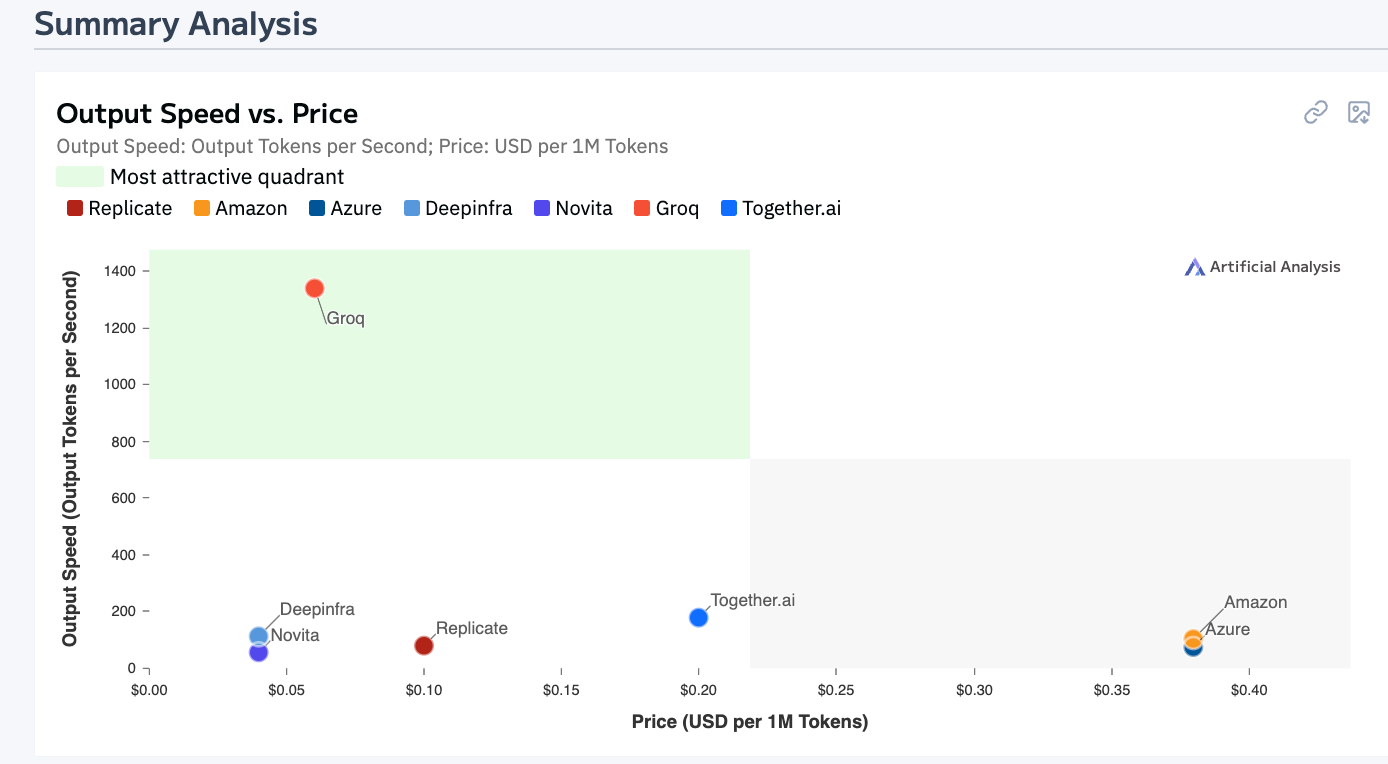
Cerebras’s massive chips = they can support bigger models than Groq. The fact that they rely less on external memory = they can be blazing fast at low costs. Cerebras has datacenters in Santa Clara, Stockton, and Dallas and is building new ones in Minneapolis (Q2 2025), Oklahoma City (Q3 2025), Montreal (Q3 2025), plus undisclosed locations in the Midwest/Eastern US and Europe (Q4 2025). These buildouts are supported financially and operationally by Abu Dhabi-based G42. Cerebras has been able to attract a GPU cloud clientele of AI hotshots, Mistral, and Perplexity, and has ambitious expansion plans. The serverless inference console is, however, still in restricted access mode and is expected to pick up more steam with the official Meta Llama partnership.
Other notable mentions:
Lambda Labs, Nebius, Coreweave - GPU clouds vertically integrating
NVIDIA DGX Cloud - GPU God vertically integrating
Baseten, Replicate, Openrouter
What about APIs from OpenAI, Anthropic, Mistral, and Grok?
In addition to powering the revolutionary AI chatbots that you and I can’t live without today, many AI labs offer inference APIs to devs and businesses, and have been very successful in doing so - Throwback to when my friends and I built Drona, a WhatsApp tutor for tier 2 India using OpenAI APIs :”). OpenAI commendably sells almost (if not more) as many dollars via its native API as Microsoft sells through Azure OpenAI. But this is an exception, as evidenced by Anthropic (most of their sales happen via Bedrock - only 10-15% direct), more than the norm, because:
Lock in / no modular AI: Customers would prefer the option to switch between model providers / use multiple models together to avoid a single source of failure
Outsource scaling & infrastructure, and other operational overheads
Enterprise sales machinery: selling to businesses is difficult. Long lead times, navigating red tape, and wine-ing and dining CIOs are skills in themselves.
Enterprise readiness: Building capability to handle security, governance, and compliance requirements
Cost: At production volume and scale, closed-source model bills rack up quickly.
Thanks for reading!
And with that - a little abruptly, I know - we wrap up Topic 2: AI inference - one of the most foundational but quietly complex layers of the AI stack. From hyperscaler domination to upstart infra bets to the rise of API-first inference platforms, I hope this series gave you a good sense of how the inference compute pipes actually get built - and who’s building them.
Thanks so much for reading and following along. Up next: inference on the edge. Yep, we’re moving from the cloud to the device. See you soon.
If you liked the content and would like to support my efforts, here are some ways:
Subscribe! It’ll help me get new updates to you easily
Please spread the word - it’s always super encouraging when more folks engage with your project. Any S/O would be much appreciated.
Drop your constructive thoughts in the comments below - point out mistakes, suggest alternate angles, request future topics, or post other helpful resources